생성형 AI의 기능을 다양하게 알고, 코드를 볼 수 있으면 많이 성장할 수 있다.
Blocks 사용하기
import numpy as np
import gradio as gr
def flip_text(x):
return x[::-1]
def flip_image(x):
return np.fliplr(x)
with gr.Blocks() as demo:
gr.Markdown("Flip text or image files using this demo.")
gr.Markdown("# Flip text")
text_input = gr.Textbox()
text_output = gr.Textbox()
text_button = gr.Button("Flip")
gr.Markdown("# Flip Image")
image_input = gr.Image()
image_output = gr.Image()
image_button = gr.Button("Flip")
with gr.Accordion("Open for More!"):
gr.Markdown("Look at me...")
text_button.click(flip_text, inputs=text_input, outputs=text_output)
image_button.click(flip_image, inputs=image_input, outputs=image_output)
demo.launch(share=True)
transformers 라이브러리의 pipeline
- feature-extraction : 특징 추출 (텍스트에 대한 벡터 표현 추출)
- fill-mask : 마스크 채우기
- ner : 개체명 인식 (named entity recognition)
- question-answering : 질의 응답
- sentiment-analysis : 감정 분석
- summarization : 요약
- text-generation : 텍스트 생성
- translation : 번역
- zero-shot-classification : 제로샷 분류
Zero-shot Classification이란?
Zero-shot classification은 모델이 학습 중에 본 적 없는 카테고리에 대한 데이터를 분류할 수 있게 하는 기술입니다. 다시 말해, 모델은 학습 데이터셋에 없는 새로운 카테고리의 데이터를 예측할 수 있습니다.
왜 Zero-shot Classification이 중요한가?
전통적인 분류 모델은 학습 중에 본 카테고리만 분류할 수 있습니다. 그러나 실제 세계의 데이터는 항상 변하고 있기 때문에, 모델이 학습 중에 본 적 없는 새로운 카테고리의 데이터를 처리할 수 있도록 하는 것이 중요합니다. Zero-shot classification은 이러한 문제를 해결하는 방법 중 하나입니다.
Zero-shot Classification 코드 예시
from transformers import pipeline
import gradio as gr
# examples = "This is a course about the Transformers library"
# labels = "education", "politics", "business"
# Zero-shot classifier 초기화
classifier = pipeline("zero-shot-classification")
def classify_text(text, labels):
labels = labels.split(",") # 쉼표로 구분된 레이블을 리스트로 변환
result = classifier(text, candidate_labels=labels)
# 결과 딕셔너리 생성
result_dict = {}
for i in range(len(result["labels"])):
result_dict[result["labels"][i]] = result["scores"][i]
return result_dict
# Gradio 인터페이스 설정
interface = gr.Interface(
fn=classify_text,
inputs=[
gr.Textbox(label="Text to Classify"),
gr.Textbox(label="Candidate Labels (comma separated)")
],
outputs=gr.Label(label="Classification Results", num_top_classes=3),
)
# 인터페이스 실행
interface.launch(share=True)
Sentiment Analysis(감정 분석)란?
감정 분석은 주어진 텍스트에서 감정 또는 의견을 판단하는 작업입니다. 주로 "긍정적", "부정적", "중립적"과 같은 카테고리로 분류됩니다. 예를 들어, 제품 리뷰, 영화 리뷰, 소셜 미디어 게시물 등에서 사용자의 감정을 분석하는 데 사용됩니다.
감정분석 예시
from transformers import pipeline
import gradio as gr
# Hugging Face의 pipeline을 사용하여 감정 분석 모델을 초기화합니다.
classifier = pipeline("sentiment-analysis")
# 감정 분석을 수행하는 함수를 정의합니다.
def sentiment_analysis(text):
result = classifier(text)
return result[0]
# Gradio 인터페이스를 설정합니다.
iface = gr.Interface(
fn=sentiment_analysis, # 위에서 정의한 함수를 사용합니다.
inputs=gr.Textbox(label="Input Text"), # 텍스트 입력 상자를 생성합니다.
outputs="json", # 출력 형태를 JSON으로 설정합니다.
examples=["I love this!", "I hate this."] # 예시 입력을 제공합니다.
)
# 인터페이스를 실행합니다.
iface.launch()
개체명 인식(Named entity recognition)
모델이 입력 텍스트의 어느 부분이 사람, 장소, 기관 등과 같은 개체에 해당하는지 찾는 작업을 개체명 인식(NER)이라고 합니다.
from transformers import pipeline
import gradio as gr
# NER pipeline 초기화
ner = pipeline("ner", grouped_entities=True)
def extract_entities(text):
result = ner(text)
entities = {}
for entity_group in result:
entities[entity_group['word']] = [entity_group['entity_group'], entity_group['score']]
print(entities)
return entities
# Gradio 인터페이스 설정
iface = gr.Interface(
fn=extract_entities,
inputs=gr.Textbox(label="Text for NER"),
outputs=gr.Textbox(label="Extracted Entities")
)
# 인터페이스 실행
iface.launch(debug=True, share=True)
# My name is Jiwoong and I work at Spartacoding Club in Seoul.
음성인식
from transformers import pipeline
import gradio as gr
asr = pipeline("automatic-speech-recognition", "facebook/wav2vec2-base-960h")
classifier = pipeline("text-classification")
def speech_to_text(speech):
text = asr(speech)["text"]
return text
def text_to_sentiment(text):
sentiment_label = classifier(text)[0]["label"]
sentiment_score = round(classifier(text)[0]['score'] * 100, 2)
return (sentiment_label, sentiment_score)
demo = gr.Blocks()
with demo:
audio_file = gr.Audio(type="filepath")
text = gr.Textbox()
label = gr.Label()
text1 = gr.Textbox()
b1 = gr.Button("Recognize Speech")
b2 = gr.Button("Classify Sentiment")
b1.click(speech_to_text, inputs=audio_file, outputs=text)
b2.click(text_to_sentiment, inputs=text, outputs=[label, text1])
demo.launch()
이미지 인식
from transformers import pipeline
import gradio as gr
# 이미지 분류 pipeline 초기화
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
def classify_image(image):
results = pipe(image)
return {result['label']: result['score'] for result in results}
# Gradio 인터페이스 설정
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="pil", label="Input Image"),
outputs=gr.Label(num_top_classes=3, label="Classification Results")
)
# 인터페이스 실행
iface.launch()
HW. 요약 인공지능 만들기
from transformers import pipeline
import gradio as gr
def summarize(input):
generator = pipeline("summarization")
output = generator(input, max_length=20)
return output[0]['summary_text']
interface = gr.Interface(
fn=summarize,
inputs=["text"],
outputs="text",
description="문제가 생기면 Flag를 누르세요.",
flagging_options = ["good", "bad", "error"],
theme=gr.themes.Soft(),
)
interface.launch()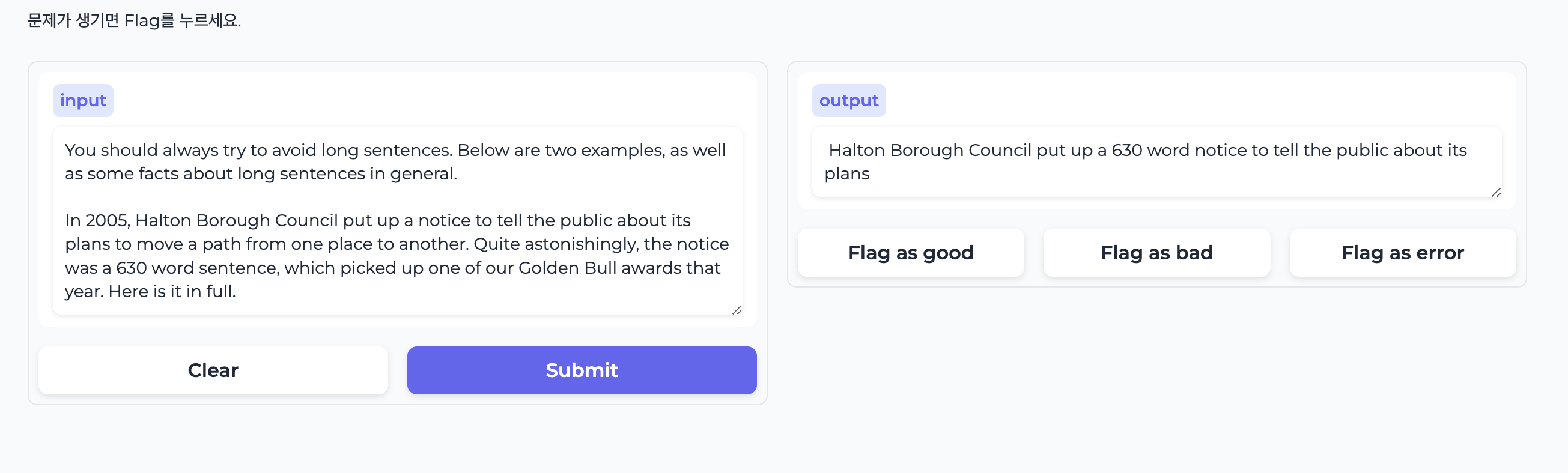
한 줄의 문장을 출력하기까지 속도가 현저히 오래 걸려서 사람들이 왜 파이썬 하면 알고리즘 인공지능이라고 하는지 알게 되었다.
시간 복잡도를 줄이는 것이 관건인 것 같다.
'학습 내용 정리 > AI' 카테고리의 다른 글
| AI가 처음이어도 쉽게 배우는 생성형 AI 1주차 (2) | 2024.07.20 |
|---|---|
| streamlit을 활용한 웹 서비스 개발 3주차 (0) | 2024.07.19 |
| streamlit을 활용한 웹 서비스 개발 2주차 (0) | 2024.07.19 |
| streamlit을 활용한 웹 서비스 개발 1주차 (2) | 2024.07.19 |



